

はじめに
「CRMを導入したのに、なんだか使いにくい...」 「同じお客様の情報があちこちに散らばってて、どれが最新かわからない」 「チームメンバーごとに入力方法がバラバラで、データ分析どころじゃない」
こんな悩み、抱えていませんか?
実は、CRM導入企業の約60%が「データの質」に課題を感じているんです。(参考:Datelere)せっかく高いお金を払ってCRMを導入したのに、肝心のデータがグチャグチャだと、宝の持ち腐れになってしまいますよね。
でも安心してください。データ整備って、実は正しい手順を踏めば、誰でもできるんです。今回は、特に多い3つの課題「一意のIDがない」「重複データだらけ」「入力方法がバラバラ」を中心に、明日から使える具体的な解決方法をお伝えします。
なぜCRMのデータ整備が売上に直結するのか
データの質が営業成果を左右する理由
みなさん、こんな経験ありませんか?「あのお客様、前に誰か訪問してたっけ?」と思ってCRMを検索したら、同じ会社名が5件も出てきて、どれが正しいのかわからない...。結局、お客様に「以前お伺いした者がおりまして...」と曖昧な話しかできず、信頼を失ってしまう。
これ、データ整備ができていないCRMあるあるなんです。
| データが汚い場合の影響 | 具体的な損失 | 改善後の効果 |
|---|---|---|
| 重複データによる混乱 | 顧客対応に平均15分の無駄 | 対応時間を50%削減 |
| IDがないため追跡不可 | 商談履歴の30%が行方不明 | 全商談を100%可視化 |
| 入力のバラつき | 分析精度が40%低下 | 正確な売上予測が可能に |
データ整備をすることで、営業チームの生産性は平均で25〜30%向上すると言われています。つまり、8時間の仕事が6時間で終わるようになるんです。残りの2時間で、新規開拓や既存顧客のフォローに時間を使えたら、売上はどれだけ伸びるでしょうか?
課題1:一意のIDがない問題を解決する
なぜ一意のIDが必要なのか
「ID」って聞くと、なんだか難しそう...と思うかもしれません。でも、これ、実はめちゃくちゃシンプルな話なんです。
例えば、「田中太郎さん」という名前の人が社内に3人いたとします。メールで「田中さんにお願いしたい」と言われても、どの田中さんかわからないですよね?でも、社員番号があれば「社員番号A001の田中さん」と特定できます。これが一意のIDの役割です。
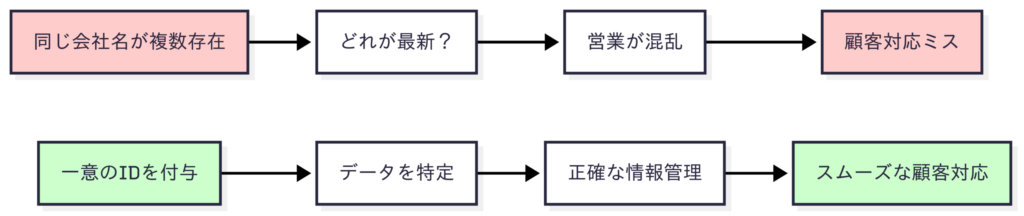
具体的なID付与の方法
それでは、実際にどうやってIDを付けていけばいいのか、ステップバイステップで説明しますね。
ステップ1:現状のデータを棚卸しする
まずは、今あるデータにどんな項目があるのか確認しましょう。エクセルやCSVでエクスポートして、全体像を把握することから始めます。
| 確認項目 | チェックポイント | 対応方法 |
|---|---|---|
| 既存のID項目 | 顧客コード、管理番号などがあるか | あれば活用、なければ新規作成 |
| データの総数 | 何件のデータがあるか | 桁数を決める参考にする |
| カテゴリー分け | 法人/個人、地域など | IDの先頭文字で分類可能 |
ステップ2:ID体系を設計する
IDの付け方には、いくつかのパターンがあります。ここでは、実務で使いやすい3つの方法を紹介します。
| ID体系 | 例 | メリット | デメリット |
|---|---|---|---|
| 連番型 | 000001, 000002... | シンプルで管理しやすい | 意味がわかりにくい |
| カテゴリー+連番型 | C-000001(法人) P-000001(個人) | 一目で分類がわかる | カテゴリー変更時に困る |
| 日付+連番型 | 202501-001 | 登録時期がわかる | 桁数が多くなる |
個人的におすすめなのは、カテゴリー+連番型です。パッと見てどんな顧客かわかるので、日々の業務で使いやすいんですよね。
なお、一般的なCRMであれば、データに一意のIDが付与されますのでそれを使うものおすすめです。例)HubspotならレコードID
ステップ3:既存データにIDを付与する
さて、いよいよ実際にIDを付けていきます。ここで大事なのは、一気に全部やろうとしないこと。まずは重要な顧客から順番に進めていきましょう。
エクセルを使った具体的な付与方法もお伝えしますね。CONCATENATE関数(文字列を結合する関数)を使えば、簡単にIDを生成できます。
例:=CONCATENATE("C-",TEXT(ROW()-1,"000000"))
これで「C-000001」「C-000002」と自動的にIDが生成されます。
課題2:重複データを見つけて統合する
重複が起きる原因と影響
「株式会社ABC」「ABC株式会社」「(株)ABC」「ABC」...同じ会社なのに、なんでこんなにバラバラに登録されちゃうんでしょうか?
実は、これには3つの主な原因があるんです。
| 重複の原因 | 具体例 |
|---|---|
| 表記ゆれ | 株式会社の位置、カタカナ/ひらがな |
| 入力ミス | タイポ、漢字の間違い |
| 複数経路からの登録 | Web問い合わせ、名刺交換、紹介 |
重複データがあると、同じお客様に複数の営業担当が別々にアプローチしてしまうなんてことが多発します。これ、お客様からしたら「この会社、大丈夫?」って思われちゃいますよね。
重複データの見つけ方
重複を見つけるには、いくつかのアプローチがあります。順番に試していくことで、かなりの重複を発見できます。
方法1:完全一致で検索
まずは、完全に同じデータを探します。CRMの重複チェック機能やエクセルの「重複の削除」機能を使えば、簡単に見つけられます。
方法2:部分一致で検索
次に、会社名の一部が一致するものを探します。例えば「ABC」で検索すると、「株式会社ABC」も「ABC商事」も出てきます。
| 検索キーワード | 見つかるパターン | 注意点 |
|---|---|---|
| 会社名の主要部分 | 前後の株式会社を除いた部分 | 略称も確認する |
| 電話番号 | ハイフンあり/なし両方 | 代表番号と直通番号 |
| メールドメイン | @以降の部分 | グループ会社に注意 |
方法3:あいまい検索を活用
ちょっと高度ですが、ファジーマッチング(あいまい一致)という方法もあります。「トウキョウ」と「東京」、「2」と「二」なども同じものとして検索できるんです。
エクセルのFuzzy Lookupアドインや、専門のデータクレンジングツールを使うと、こういった検索ができます。ただ、最初は手動でチェックする方が確実かもしれません。
重複データの統合手順
重複が見つかったら、次は統合です。ここで大切なのは、どのデータを残すかの基準を決めること。
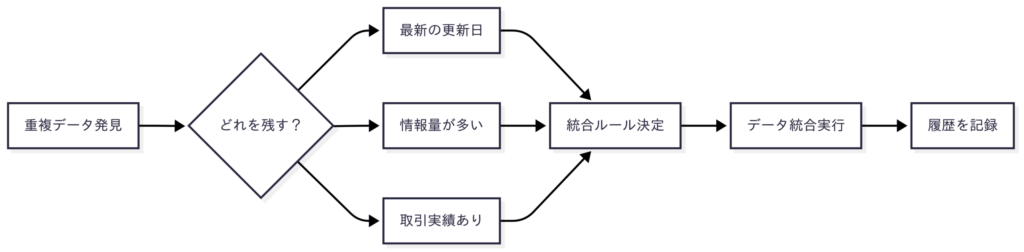
統合時のチェックリスト
統合する前に、必ず以下の項目を確認しましょう。
| 確認項目 | なぜ重要? | 対応方法 |
|---|---|---|
| 商談履歴 | 過去の経緯がわからなくなる | 全履歴を1つに集約 |
| 担当者情報 | 複数の窓口がある場合 | 部署ごとに整理 |
| 請求先情報 | 経理処理に影響 | 最新の情報を優先 |
| 関連ファイル | 提案書や契約書 | すべて移行する |
統合作業は慎重に行う必要がありますが、一度きれいにすれば、その後の業務効率は格段に上がります。最初は大変でも、頑張る価値は十分にあります!
課題3:入力ルールを統一する
なぜ入力がバラバラになるのか
「東京都渋谷区」「渋谷区」「東京 渋谷」...同じ住所なのに、人によって入力方法が違う。「メルカリ(株)」、「(株)メルカリ」、「メルカリ」「mercari」...同じ会社なのに、人によって入力方法が違う。これ、あるあるですよね。
実は、入力がバラバラになる背景には、こんな理由があります。
| バラつきの原因 | 具体例 | 影響度 |
|---|---|---|
| ルールが明文化されていない | 「なんとなく」で入力 | ★★★★★ |
| 研修不足 | 新人が独自の方法で入力 | ★★★★☆ |
| 過去の習慣 | 前職のやり方を引きずる | ★★★☆☆ |
| システムの制約 | 文字数制限で省略 | ★★☆☆☆ |
特に問題なのが、ルールがないこと。みんな悪気はないんです。ただ、基準がないから、それぞれが「これが正しい」と思う方法で入力しちゃうんですよね。
入力ルールの作り方
じゃあ、どうやってルールを作ればいいのか?ポイントはシンプルで覚えやすいルールにすることです。
基本の入力ルール例
まずは、よく使う項目の基本ルールを決めましょう。
| 項目 | ルール | 良い例 | 悪い例 |
|---|---|---|---|
| 会社名 | 正式名称、株式会社は前 | 株式会社ABC商事 | ABC商事(株) |
| 電話番号 | ハイフンあり、市外局番から、半角数字 | 03-1234-5678 | 1234-5678 |
| 住所 | 都道府県から、建物名まで | 東京都渋谷区1-1-1 ABCビル5F | 渋谷1-1-1 |
| 担当者名 | 姓名の間に全角スペース | 田中 太郎 | 田中太郎 |
| 日付 | YYYY/MM/DD形式 | 2025/01/15 | 25/1/15 |
プルダウンやチェックボックスの活用
自由入力を減らすことも、バラつきを防ぐ重要なポイントです。
例えば、都道府県や業種、役職などは、プルダウンにしちゃえば、入力のブレはなくなります。最初に選択肢を作る手間はありますが、長期的に見れば絶対にお得です。
チーム全体で統一するための工夫
ルールを作っても、守られなければ意味がありません。どうやってチーム全体に浸透させるか、これがどの企業も一番の課題かもしれません。
1. わかりやすいマニュアルを作る
文字だけのマニュアルって、正直読む気しないですよね。だから、ビジュアル重視で作りましょう。
| マニュアルの要素 | 作り方のコツ |
|---|---|
| スクリーンショット | 実際の画面を使って説明 |
| ○×例 | 良い例と悪い例を並べる |
| クイックリファレンス | A4一枚にまとめた簡易版 |
| FAQ | よくある質問と回答 |
2. 定期的なチェックとフィードバック
月に1回、データの品質をチェックする日を作りましょう。「データクリーンアップDay」なんて名前をつけて、イベント化するのもおすすめです。
チェック項目はこんな感じで:
- 先月の新規登録データの入力ルール遵守率
- よくある間違いパターンのピックアップ
- 改善提案の募集
3. システムで制御する
可能であれば、システム側で入力を制御するのが一番確実です。
| 制御方法 | 具体例 | 効果 |
|---|---|---|
| 入力必須設定 | 重要項目は空欄不可 | データ欠損を防ぐ |
| 文字数制限 | 電話番号は13文字固定 | 形式を統一 |
| 形式チェック | メールアドレスの@チェック | 入力ミスを防ぐ |
| 重複チェック | 登録時に既存データと照合 | 重複を未然に防ぐ |
実践!データ整備の進め方
フェーズ分けで無理なく進める
さて、ここまで3つの課題と解決方法を見てきました。でも、「全部一気にやるのは無理!」って思いますよね。その通りです。だから、フェーズを分けて進めていきましょう。
Phase1:現状把握と計画(2週間)
まずは、今のデータがどんな状態なのか、しっかり把握することから始めます。
| タスク | 期間 | 成果物 |
|---|---|---|
| データ品質の診断 | 3日 | 現状分析レポート |
| 影響度の評価 | 2日 | リスク評価シート |
| 整備計画の作成 | 3日 | プロジェクト計画書 |
| 体制の決定 | 2日 | 役割分担表 |
| ツールの選定 | 4日 | ツール比較表 |
この段階で大事なのは、完璧を求めすぎないこと。8割の精度でいいので、まずは全体像を掴むことに集中しましょう。
Phase2:重要データから着手(3週間)
次に、ビジネスインパクトが大きい重要データから整備を始めます。パレートの法則(80対20の法則)で考えると、上位20%の顧客が売上の80%を占めていることが多いんです。だから、この20%から始めるのが効率的。
Phase3:ルール作りと周知(2週間)
データ整備と並行して、今後のためのルール作りも進めます。ここでのポイントは、現場の声を聞くこと。机上の空論にならないよう、実際に入力する人たちの意見を必ず取り入れましょう。
Phase4:全体展開と定着(2ヶ月)
最後に、全データの整備と、新しいルールの定着を図ります。この段階では、小さな成功体験を積み重ねることが大切。「データがきれいになったら、レポート作成が30分短縮できた!」みたいな成果を共有していくと、モチベーションも上がりますよ。
ツールを使った効率化
データ整備を手作業だけでやるのは、正直しんどいです。そこで、便利なツールを活用しましょう。
| ツールカテゴリー | 代表的なツール | 特徴 | 価格帯 |
|---|---|---|---|
| データクレンジング | OpenRefine(無料) | 重複削除、表記統一 | 無料 |
| ETLツール | Talend Open Studio | データ変換、統合 | 無料〜 |
| CRM標準機能 | Salesforce、Hubspotの重複管理 | リアルタイム重複チェック | CRM費用に含む |
| エクセルアドイン | Fuzzy Lookup | あいまい一致検索 | 無料 |
最初は無料ツールから始めて、効果を実感できたら有料ツールを検討する、という流れがおすすめです。いきなり高額なツールを導入しても、使いこなせなければ意味がありませんからね。
成果を測定する指標
データ整備の効果って、どうやって測ればいいんでしょうか?実は、具体的な数字で追える指標がいくつかあるんです。
| 測定指標 | 計算方法 | 目標値 |
|---|---|---|
| データ完全性 | 必須項目の入力率 | 95%以上 |
| 重複率 | 重複データ数÷全データ数 | 3%以下 |
| 準拠率 | ルール通りの入力数÷全入力数 | 90%以上 |
| 更新頻度 | 3ヶ月以内に更新されたデータの割合 | 80%以上 |
これらの数字を月次でトラッキングして、改善傾向をグラフ化すると、経営層への報告もしやすくなります。「データ整備なんて地味な作業...」と思われがちですが、数字で成果を示せば、その重要性を理解してもらえるはずです。
よくある失敗パターンと対策
失敗パターン1:完璧主義の罠
「せっかくやるなら、100%完璧なデータにしたい!」
この気持ち、すごくわかります。でも、これが一番危険な落とし穴なんです。完璧を求めすぎると、いつまでも作業が終わらず、結局途中で挫折してしまうことが多いんですよね。
対策は、段階的なゴール設定です。

まずは60%でいいんです。それでも、何もしないよりは格段に業務が楽になります。小さな成功を積み重ねながら、徐々に品質を上げていきましょう。
失敗パターン2:現場の巻き込み不足
「上からの指示でデータ整備することになったから、よろしく」
これでは、現場は動きません。なぜなら、メリットが見えないから。データ整備って、正直面倒な作業です。その面倒さを上回るメリットを、しっかり伝える必要があります。
| 現場の本音 | 伝えるべきメリット |
|---|---|
| 「今でも何とかなってる」 | 月末の集計作業が2時間→30分に短縮 |
| 「入力が面倒になる」 | プルダウン化で入力時間は逆に削減 |
| 「ミスしたら怒られそう」 | システムでチェックするから安心 |
| 「自分には関係ない」 | 顧客満足度向上→評価アップ |
失敗パターン3:メンテナンスの仕組み不在
せっかくデータをきれいにしても、1ヶ月後にはまた汚くなっている...これもよくある失敗です。原因は、継続的にメンテナンスする仕組みがないから。
対策として、以下の仕組みを作りましょう:
| タイミング | 実施内容 | 担当者 | 所要時間 |
|---|---|---|---|
| 毎日 | 新規登録データのチェック | 当番制 | 15分 |
| 週次 | 重複データの確認 | データ管理者 | 30分 |
| 月次 | データ品質レポート作成 | マネージャー | 1時間 |
| 四半期 | ルールの見直し | 全員参加 | 2時間 |
大事なのは、無理のない範囲で継続すること。最初から完璧なメンテナンス体制を作ろうとすると、結局続きません。まずは週1回、30分だけでもいいので、定期的にチェックする習慣をつけることから始めましょう。
まとめ
長い記事になってしまいましたが、ここまで読んでいただき、ありがとうございます!最後に、今回お伝えした内容を振り返ってみましょう。
Key Takeaways
📍 データ整備は売上に直結する重要な投資
- きれいなデータは営業効率を25-30%向上させる
- 顧客対応の質が上がり、信頼関係が強化される
- 正確な分析により、的確な経営判断が可能になる
📍 3つの主要課題には具体的な解決策がある
- 一意のID:カテゴリー+連番型がおすすめ
- 重複データ:段階的なチェックと統合ルールの明確化
- 入力のバラつき:シンプルなルールとシステム制御の組み合わせ
📍 フェーズ分けで着実に進めることが成功の鍵
- Phase1:現状把握(2週間)
- Phase2:重要データから着手(3週間)
- Phase3:ルール作りと周知(2週間)
- Phase4:全体展開と定着(2ヶ月)
📍 完璧を求めすぎない、でも継続は必須
- 60%の品質でもスタートする勇気を持つ
- 現場のメリットを明確に伝えて巻き込む
- 週1回30分でもいいから定期メンテナンスを習慣化
📍 ツールを活用して効率化を図る
- 無料ツールから始めて効果を確認
- CRMの標準機能を最大限活用
- 必要に応じて専門ツールを検討
データ整備って、確かに地味で面倒な作業です。でも、これができているかどうかで、1年後の会社の成長速度が全然違ってくるんです。
今日から始められることは、まず現状のデータを1時間だけでもチェックしてみること。どんな問題があるのか、それを知ることが第一歩です。
CRMは単なるデータベースじゃありません。会社の財産であり、成長のエンジンです。その財産を磨き上げることで、きっとあなたのビジネスは次のステージに進めるはずです。
データ整備、一緒に頑張っていきましょう!何か困ったことがあれば、このブログでまた詳しく解説していきますので、ぜひチェックしてくださいね。

